Overview¶
This Scrapy project uses Redis and Kafka to create a distributed on demand scraping cluster.
The goal is to distribute seed URLs among many waiting spider instances, whose requests are coordinated via Redis. Any other crawls those trigger, as a result of frontier expansion or depth traversal, will also be distributed among all workers in the cluster.
The input to the system is a set of Kafka topics and the output is a set of Kafka topics. Raw HTML and assets are crawled interactively, spidered, and output to the log. For easy local development, you can also disable the Kafka portions and work with the spider entirely via Redis, although this is not recommended due to the serialization of the crawl requests.
Dependencies¶
Please see the requirements.txt within each sub project for Pip package dependencies.
Other important components required to run the cluster
- Python 2.7: https://www.python.org/downloads/
- Redis: http://redis.io
- Zookeeper: https://zookeeper.apache.org
- Kafka: http://kafka.apache.org
Core Concepts¶
This project tries to bring together a bunch of new concepts to Scrapy and large scale distributed crawling in general. Some bullet points include:
- The spiders are dynamic and on demand, meaning that they allow the arbitrary collection of any web page that is submitted to the scraping cluster
- Scale Scrapy instances across a single machine or multiple machines
- Coordinate and prioritize their scraping effort for desired sites
- Persist data across scraping jobs
- Execute multiple scraping jobs concurrently
- Allows for in depth access into the information about your scraping job, what is upcoming, and how the sites are ranked
- Allows you to arbitrarily add/remove/scale your scrapers from the pool without loss of data or downtime
- Utilizes Apache Kafka as a data bus for any application to interact with the scraping cluster (submit jobs, get info, stop jobs, view results)
- Allows for coordinated throttling of crawls from independent spiders on separate machines, but behind the same IP Address
Architecture¶
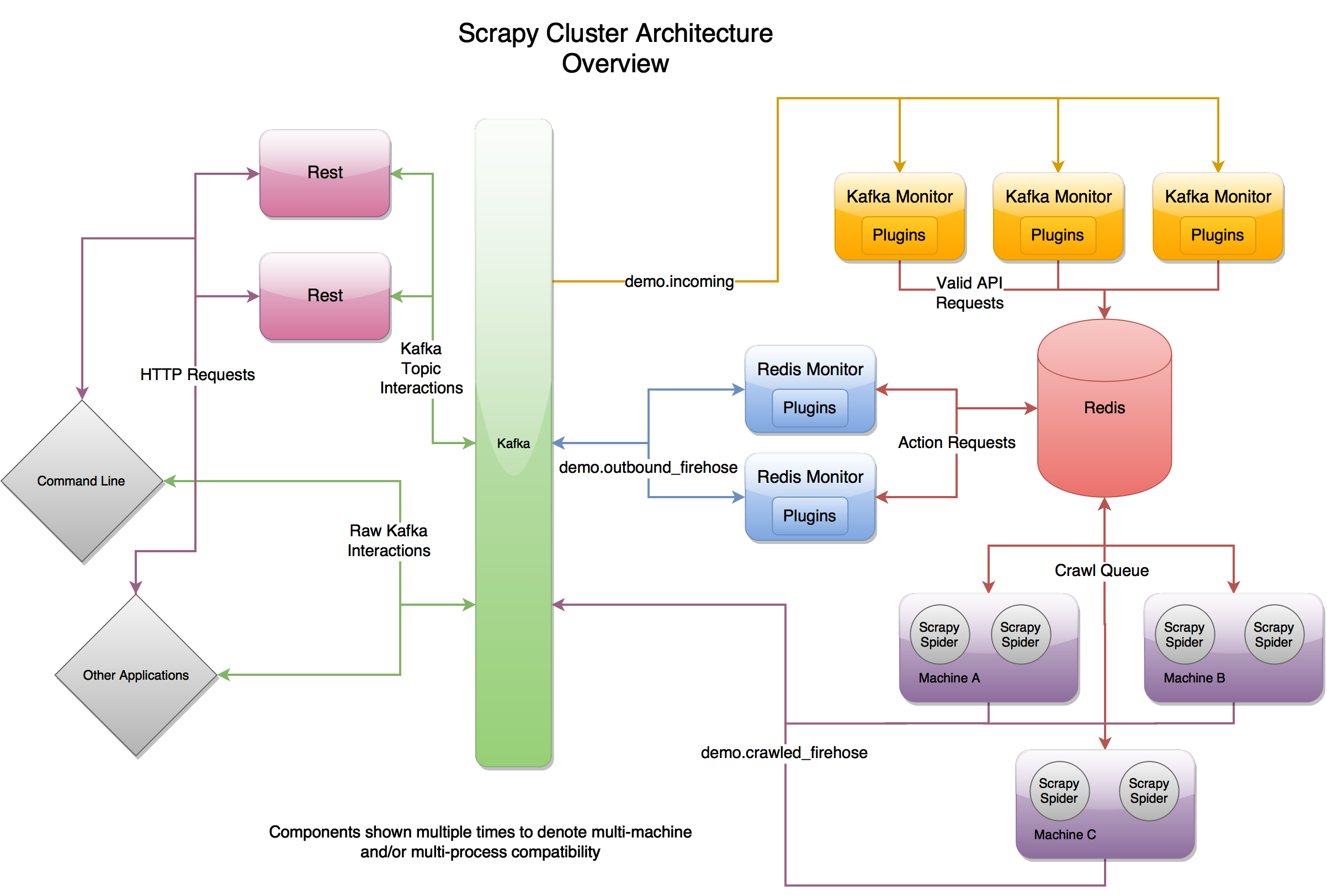
At the highest level, Scrapy Cluster operates on a single input Kafka topic, and two separate output Kafka topics. All incoming requests to the cluster go through the demo.incoming kafka topic, and depending on what the request is will generate output from either the demo.outbound_firehose topic for action requests or demo.crawled_firehose topics for html crawl requests.
Each of the three core pieces are extendable in order add or enhance their functionality. Both the Kafka Monitor and Redis Monitor use ‘Plugins’ in order to enhance their abilities, whereas Scrapy uses ‘Middlewares’, ‘Pipelines’, and ‘Spiders’ to allow you to customize your crawling. Together these three components and the Rest service allow for scaled and distributed crawling across many machines.